
Image Prior: Modeling Spatial Relaionship
Materials: https://www.cse.wustl.edu/~ayan/courses/cse659a/lec1.html#/
- Image Prior: Modeling Spatial Relaionship
- Smoothing Regularization
- Learning Image Prior
This is the basis for most further applications
We need Regularizer for a spatial configuration
ˆX=argminXϕ(X)+R(X)This could be interpreted in a Bayesian way,
ˆX=argmaxXP(X|I)P(I)=argmaxXlogexp(−ϕ(X))+logexp(−R(X))Smoothing Regularization
Images (and labels) are smooth (Gradients are small) !
R(X)=∑n∑fR(∇f∗X[n])Design Choices
- What kind of gradient to penalize
- How do you penalize (L1, L2, Lp?) (L1 penalty is better often)
How to analyze a prior?
- Find the distribution corresponding to that regularizer
- See how it affect the minimizing result of a loss
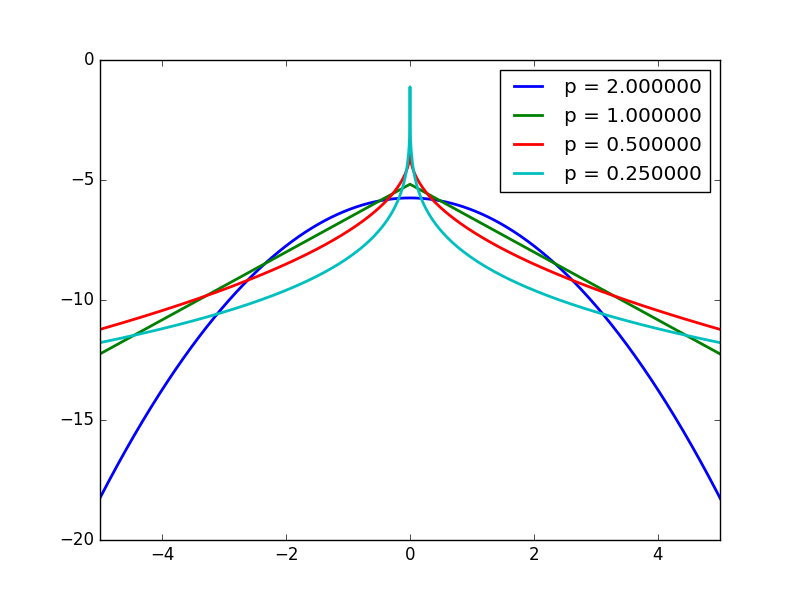
Heavy Tail Distribution
- The smaller the p (p<2) the more heavy tail distribution
- Comparing to Gaussian, More emphasis in closing to 0, or quite large!
- So it’s said to be sparse prior!
- Natural image gradients appears to be heavy tail
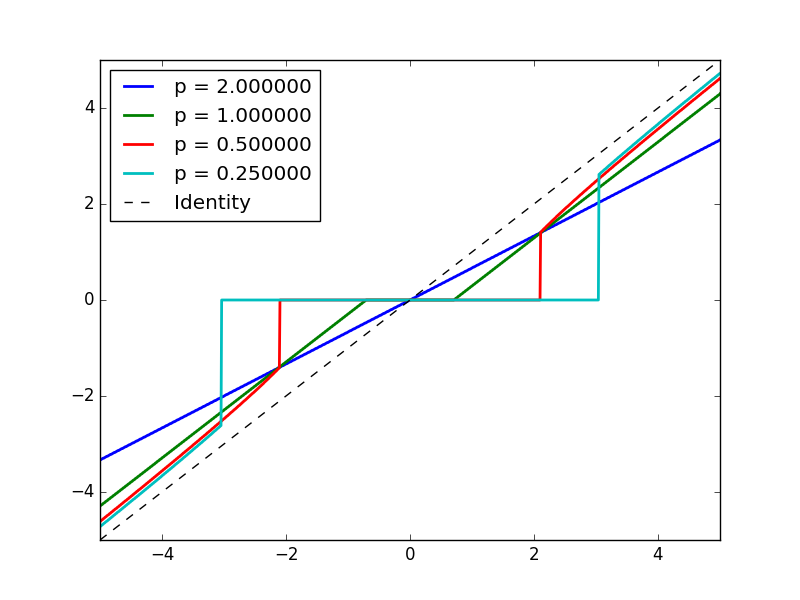
Shrinkage function
The operator defined by solving minimization with regularization
s(v0)=argminvα(v−v0)2+R(v)- L2: scale the identity line ! s(v0)=λv0
- L1: Shrink to 0 below α, offset other things linearly by α
- Lp (p<1): Shrink to 0 below α, offset other things
Thus, Heavy tail regularizer will leave small values to be 0, and penalize not as hard towards the larger values.
Solvable Case
If you use wavelet transform (unitary matrix), then
Optimization
How Lp affect optimization
- L2, it’s a Least square problem,
- Can solve in Fourier Domain, and can use conjugate gradient! (to avoid forming the matrix Q)
- L1, Convex optimization, iteratively solvable with shrinkage function
- Lp < 1, Not even convex !
Algorithms
Problem setting
ˆX=argminX‖AX−Y‖2+λ∑n|∇x∗X[n]|p+|∇y∗X[n]|pFourier Domain Least Square
If it’s
Conjugate Gradient
We can do CG if p==2
Note, if you have per pixel weight, you have to use CG, because it’s not convolution.
Iterative Reweighted Least Square (IRLS)
Rationale: We know how to solve least square, so just map the problem to least square
- Use weight to transform problem as p=2
- Solve the p=2 Least square
- Update the weights
- Iterate!
Note:
- p=1 it’s convex, so globally converging
- p<1 it’s not guanranteed, as loss is not convex.
Quadratic splitting
It’s the simplest case of Proximal method in optimization.
Basic Idea: Split the optimization variables into 2, and introduce relaxation variable
- Split the problem into 2 and let the 2 parts negotiate and compete!
Relax the problem of
argminXF(X)+G(X) Into
argminXminWF(X)+G(W)+β2‖X−W‖2 When β is large enough, this goes back to original problem
Then you can optimize the 2 variables alternatively and iteratively, if these problems are simple enough!
ˆXt=argminXF(X)+β2‖X−W‖2ˆWt=argminWG(W)+β2‖X−W‖2 And then you increase β from time to time, tighten it up! make it converge back to original problem.
Note ADMM is more principled version of this.
In our case, relax the problem as
ˆX=argminX‖AX−Y‖2+β2∑n|∇x∗X[n]−wx[n]|2+|∇y∗X[n]−wy[n]|2+|wx[n]|p+|wy[n]|p- Thus Optimization towards X can be solved by Fourier Domain Least Square.
- Optimization towards wx,wy are pixelwise 1-d optimization. Can use shrinkage function LUT to compute.
- Also increase β
Work super well in practise
- If your problem has multiple parts, these parts doesn’t work well with each other, but they all work with quadratic loss,
- Then you can try splitting your problem!
This could be applied to deblurring!
Gradient Penalty Regularizer
Maybe the function should not be applied pixel wise to gradient, it can be applied to the gradient space as a whole.
R(X)=R(∇∗X)[n]R(.) can be a function on the whole space!
- Using pixelwise regularizer is assuming independence between pixels / channels. May not be true.
- Also the operation is independent on different pixel / elements! May not be desirable.
Radial function regularizer
R(v1,v2...)=(√v21+v22+...)p=(‖v‖)pRegularizer applies to vector norm instead of individual component.
n dimension Shrinkage function [v1,v2]=argminv1,v2‖v−v0‖2+‖v‖p The result is interesting, It’s just the original shrinkage function applied to radial direction (the vector norm direction).
This could be applied to RGB image, the 3 channels are not independent.
- The pixel is shrink to 0 only if all 3 channels are small to some extant!
- Shrink 3 channel independently can cause color shifting.
Learning Image Prior
Almost universal truth
- Better prior are more complicated, harder to optimize
- Better priors are more data driven, better than hand crafted
- But if you have data, use data driven prior.
Caveat: Image itself is too high dimensional, you’d better start working with patch!
How to learn a distribution?
Choose a parametric form of distribution p(X∣θ), which you could evaluate likelihood!
Given the Samples [X1,X2…], Do maximum likelihood inference for the θ
Gaussian Prior
Training a Gaussian prior is analytically exact! Just compute the mean and covariance matrix of all your data (image patch) samples. μ=1T∑tXt,Σ=1T∑t(Xt−μ)(Xt−μ)T
Gaussian Prior Characteristics
- Normally your mean vector at small scale is equal luminance !
- If you do Eigen decomposition of covariance matrix (do PCA), Σ=VDVT then you will find interesting result
- PC1 pattern is the overall luminance
- PC2-…. looks really like Fourier Basis !!!!
- Note if your samples are translational invariant, the Fourier Basis is expected!
- Note if your images are aligned by sth., then it’s no longer translational invariant, then you will see interesting patterns around the alignment point!
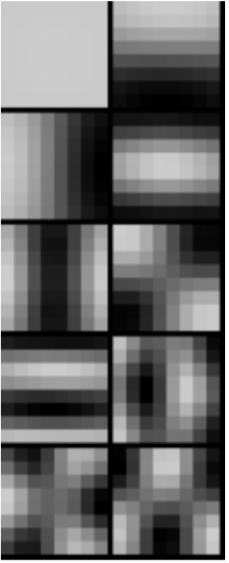
Applying Prior
Actually Gaussian prior regularizer is equivalent to regularizing a filtered image.
- Note the first PC is different!
- Usually the first eigenvalue is pretty large !
- And the distribution over the first eigenvector is not Gaussian! more uniform.
- The next few components will work like convolving Vi onto image with a squared penalty on gradients
Bayesian Interpretation of Gaussian Denoising
The posterior of 2 Gaussian multiplied is still a Gaussian! Good !
Two kinds of Bayesian estimator
- MAP, maximum / mode of the posterior argmaxXp(X∣Y)
- Mean Estimator Ep(X∣Y)(X)
Note for Gaussian, mean and mode are the same!
Gaussian Mixture Prior
p(x)=∑iπip(x;μi,Σi)∑iπi=1One step further, GMM is still a pretty good distribution.
- Mean μ=∑iπiμi
- Covariance: Consists of within gaussian term and across gaussian term (variance between the mean).
- E(X−μ)(X−μ)T=∑iπiΣi+∑iπi(μi−μ)(μi−μ)T
High Flexibility
- Multimodal
- The covariance structure is not “ellipsoidal”, it can be more restrictive, choosing between axis 1,2,3 !
- The decay is not of gaussian speed! —- heavier tail distribution!
- Choosing between close to 0,
- etc. approximation to any function, given enough components.
Note: this is also quite powerful for theoretical purpose, can use this as model of underlying distribution.
Fitting a Gaussian Mixture
Parameters: Θ=πi,μi,Σi
Bad news: likelihood non-convex!
- Note, there is internal swap symmetry of the Likelihood function, thus it’s definitely non-convex
You have to use EM algorithm.
Expectation Maximization
Think of mixture of gaussian distribution as a 2 step process.
Introduce the label variable Z∈1,2,…k with distribution
p(Z=i)=πi
The posterior distribution of X is Gaussian. p(X∣Z=i)=N(X∣μi,Σi) The variable X marginalizes as the GMM p(X)=EZp(X∣Z)=∑ip(Z=i)p(X∣Z=i) Key Observation: If you know the value of Zi for each sample (cluster belonging), then estimate the Gaussian parameters are easy.
EM Algorithm:
- Estimate Zi based on μi,Σi
- Fix Zi and estimate μi,Σi.
Properties
- Similar to K Means, just with soft assignment!
- No guanrantee of anything …..
Tricks to make it work
- One component can die! πi can go to 0 and it will not resurrect
- You need to add smallest value to constraint, or reinitialize the component manually.
- Initialization Tricks
- Do random initialization
- Try different number of K
- Heat up EM
- You can do hard K Means first and then do EM.
- Constrain EM
- You can add constraints among μi or Σi relationship, so that you have less variable.
Mixture Gaussian Patch Prior
Each component allows a certain kind of variation. It behaves like classifying the local patches first, and then regularize one kind of patch with the Gaussian estimated from PCA of training sample.
Zoran and Weiss 2011

GMM Regularizer
‖Y−X‖2−logp(X)=‖Y−X‖2−log∑iπif(X;μi,Σi)Conceptually, note that this could be think of as posterior p(X∣Y)
The posterior is also in GMM family! with the new parameters Θ′=π′i,μ′i,Σ′i
So it’s kind of adaptive Gaussian denoising. Given a patch in a image,
From Patch Prior to Image Prior
Note the priors we derived are all patch based prior. So when we denoise overlapping patches, some procedure should be taken to prevent Oversmoothing!
More principle way is to crop out patches by operator Pi and inference them as prior argminX‖AX−Y‖2−∑ilogp(PiX) Thus it could be inferenced by the Half Quadratic Splitting Trick!
Weiss & Zoran 2011 EPLL
Sparse Dictionary Regularizer
Having a few templates, and enforce that each patch should look like the linear combination of a few templates (atoms). Requires that the recombination weights are sparse, only a few non-zero entries. argmin‖X−∑iαiDi‖2
Algorithm
Dictionary learning
- Direct α learning is combinatoric hard! There are combinatorical way of active α
- Learning the templates is also hard
- SOTA algorithm K-SVD Aharon et.al.
- K-SVD talk
- K-SVD paper
Dictionary Result
Note the learned dictionary looks much like the templates, more than Fourier Basis. Thus more informative.
Comparison to GMM
- GMM: select one branch and allow a certain type of variation.
- Sparse Dictionary: Store different atoms of the image.

Refer to the advanced course.
CSE 585T Sparse Modeling for Imaging and Vision
CNN-Denoiser Based Prior
Observe that in half quadratic splitting, the prior only affects denoising, i.e. the following problem
Z=argminZβ2‖X−Z‖2−logp(Z)
So no matter your application, i.e.
X=argminX‖AX−Y‖22+β2‖X−Z‖2−logp(Z)
you can use the denoising prior!
Learning Deep Denoising Prior
Given the denoising problem, It’s easy to generate some image sample pairs (X,Z) and use them to train a CNN to fit this function Z=f(X;β)=argminZβ2‖X−Z‖2−logp(Z) So we note that we have to train a different CNN to solve the problem with a different strength of prior.