TL;DR
Two DiTs trained on the same task can reach the same accuracy via fundamentally different internal circuits. Swapping the text encoder — random token embeddings (RTE) vs. pretrained T5 — re-routes how spatial relation information reaches image tokens.
RTE-DiT learns a clean two-stage circuit: a relation head tags image positions via QK interactions, an object head renders shapes into the tagged regions. T5-DiT bypasses the relation token entirely — spatial layout is decoded from contextualized object-token embeddings (especially the second shape word). The T5 circuit collapses under small prompt perturbations; the RTE circuit does not.
Overview
Text-to-image diffusion models routinely fail to place objects in the correct spatial configuration — "a red square to the left of a blue circle" comes out swapped or merged. We ask mechanistically: when a Diffusion Transformer does get spatial relations right, how does it do it, and why does the same architecture fail under tiny prompt changes?
We train PixArt-style DiTs from scratch on a controlled two-object relational dataset, varying only the text encoder. Using a scalable attention synopsis method we identify the specific cross-attention heads that carry relational information, trace the circuit end-to-end, and verify each step with weight-space analysis, ablations, and causal embedding manipulations.

Key Findings
- Same accuracy, different circuits. Both RTE-DiT and T5-DiT reach ~84% spatial-relation accuracy, but their internal information flow is incompatible.
- Spatial relations are learned last. Training dynamics show colors, then shapes, then attribute binding, then spatial relations — the relational structure is the slowest to converge.
- RTE-DiT: a clean two-stage circuit. A spatial relation head (e.g. L2H8) writes a positional tag into image tokens via QK interaction with relation features; an object generation head reads the tag and renders the shape.
- T5-DiT: information fusion in text tokens. Spatial information leaks out of the relation word and into the contextual embedding of the second shape token. The model effectively reads "where + what" from a single token.
- Robustness diverges. Inserting an innocuous filler word (e.g. "the") drops T5-DiT spatial accuracy from 81% → 50% while RTE-DiT holds at ~84%.
- Vector arithmetic controls layout. Linear edits to factorized T5 embeddings causally swap the generated spatial relation while preserving object identity — direct evidence the relation is encoded in a linear subspace of the contextual embedding.
Attention Synopsis & Circuit Discovery
Cross-attention in a DiT produces millions of maps over training. Our attention synopsis aggregates these by token category (object words, relation word, color words, filler) and averages over diffusion timesteps, surfacing the small number of heads that consistently route relational information.
Show the static Figure 3 from the paper

Relation Circuits in DiTs

Show the static Figure 6 from the paper
RTE-DiT: two-stage relation → object pipeline


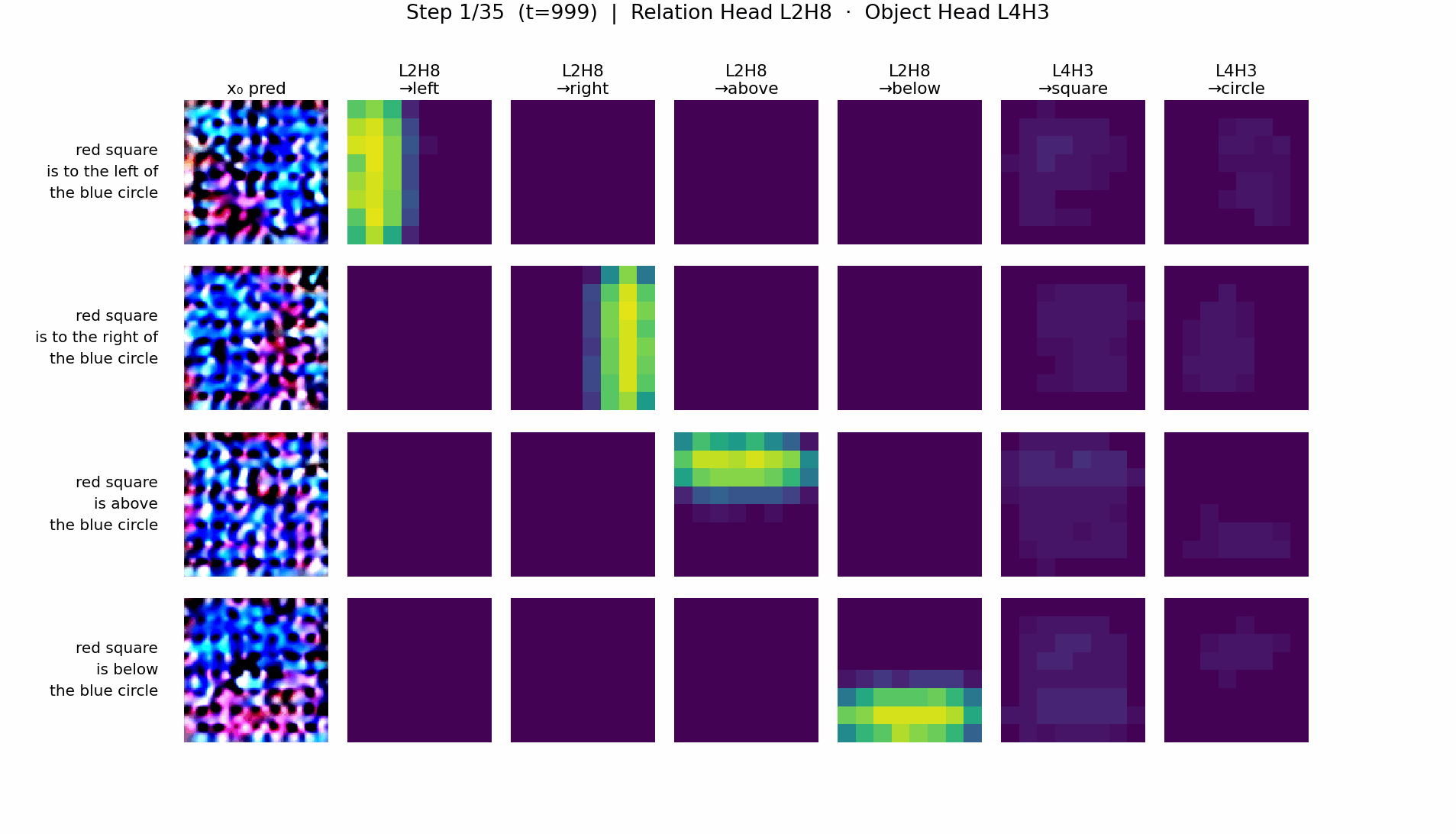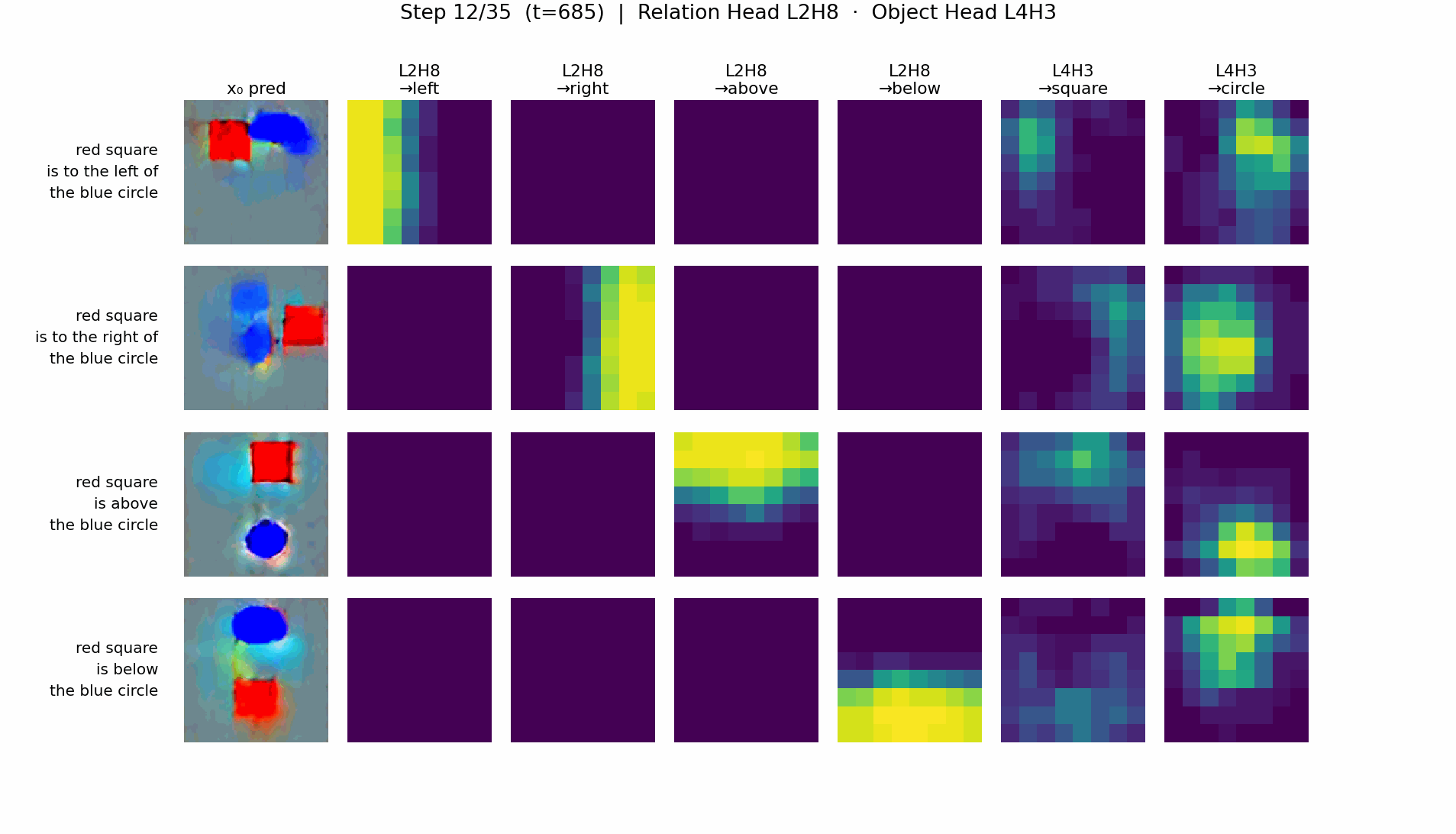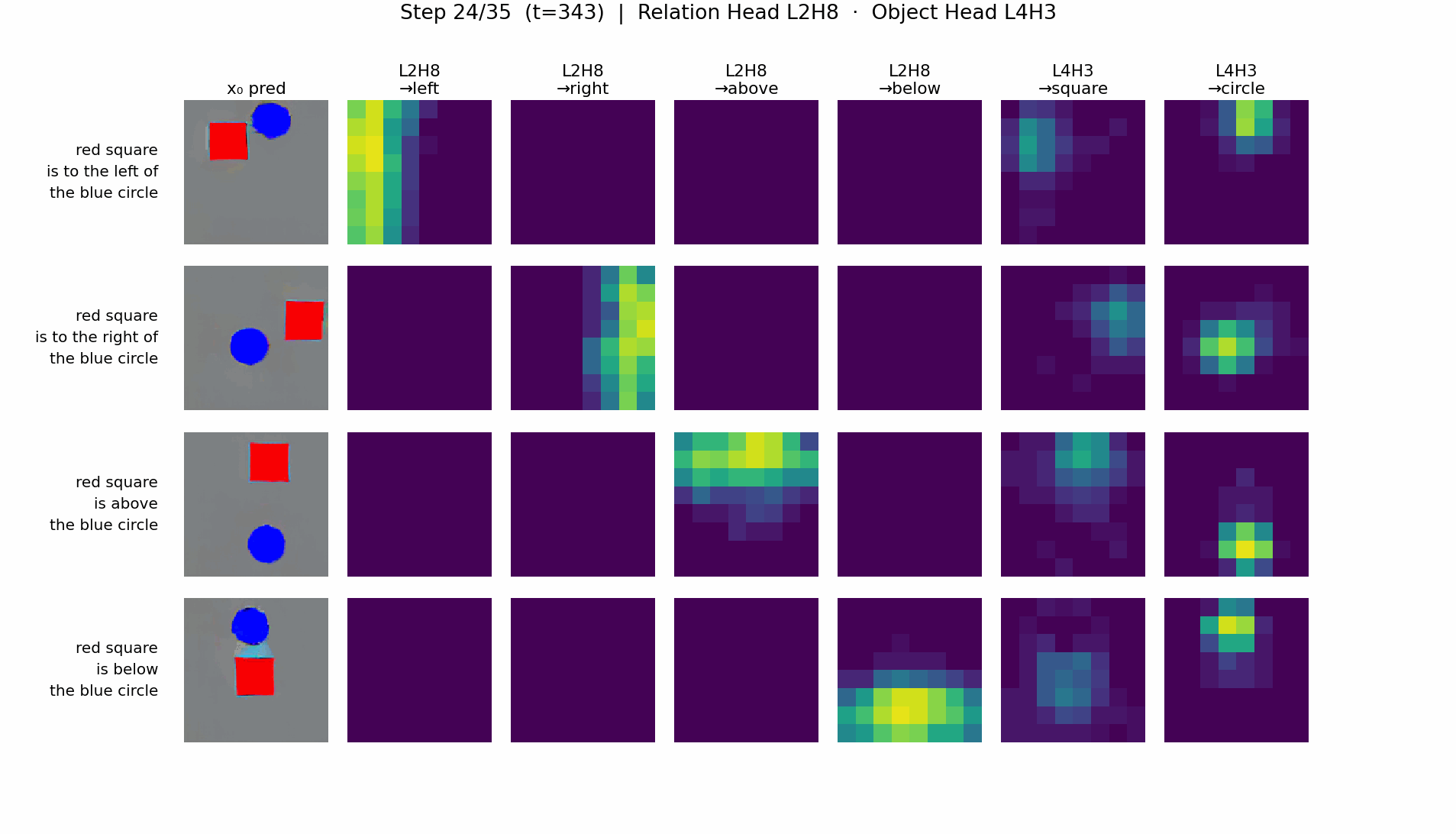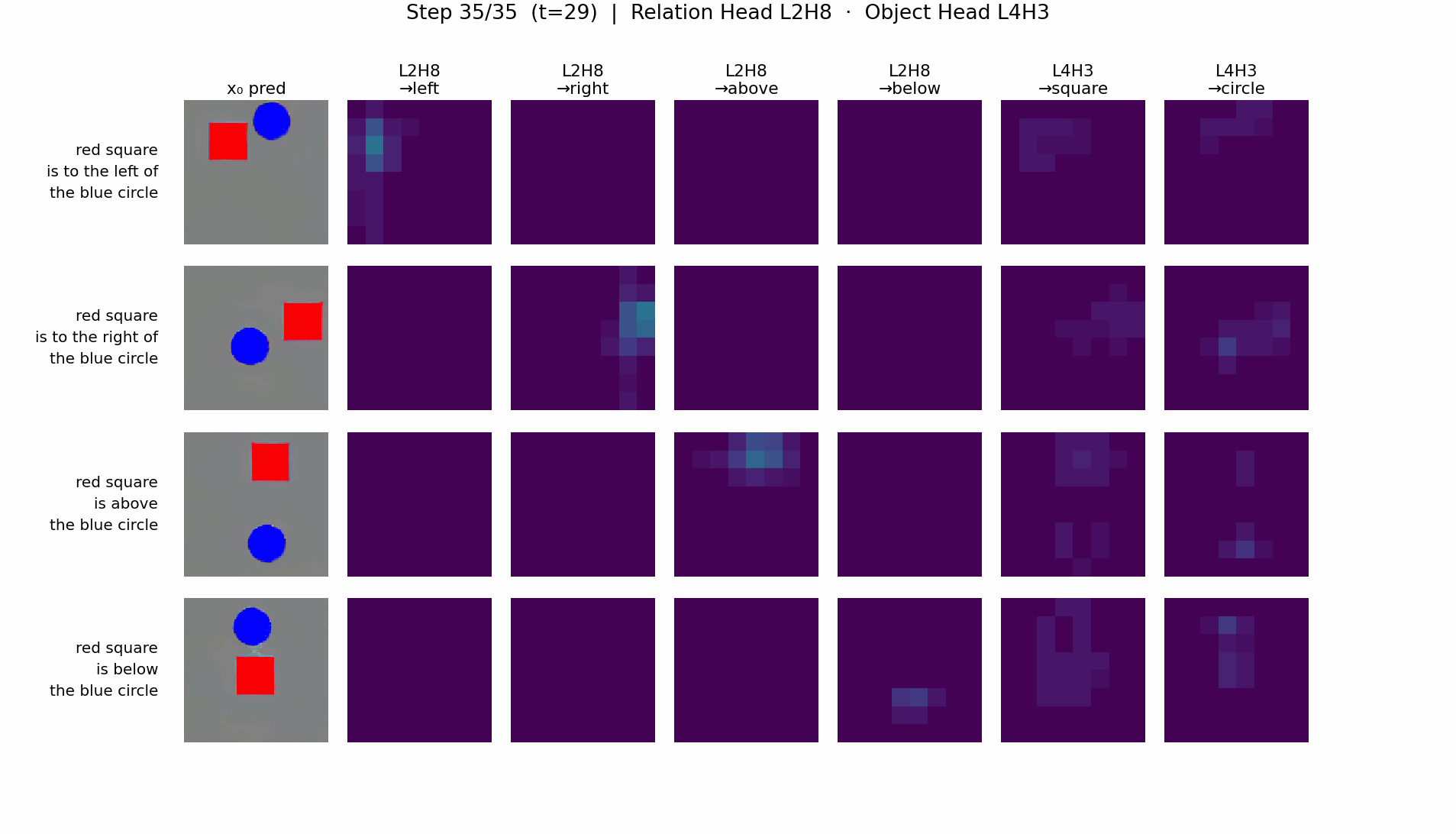
T5-DiT: information fusion in object tokens

Why this matters
The same downstream task is solvable by qualitatively different mechanisms — and which mechanism a model converges to depends on the representational substrate of the text encoder, not the diffusion backbone. T5's rich contextual fusion is an efficient solution in-distribution but creates a brittle dependence on full-sequence context; RTE's tokens, lacking pretraining priors, force the DiT to construct an explicit, modular relation circuit that generalizes more robustly.
This is a concrete case study in how pretrained encoders shape downstream circuits, and a methodological template — attention synopsis plus targeted causal interventions — for dissecting compositional behavior in diffusion models.
Citation
@inproceedings{wang2026circuit,
title = {Circuit Mechanisms for Spatial Relation Generation in Diffusion Transformers},
author = {Wang, Binxu and Fan, Jingxuan and Pan, Xu},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2026}
}
Acknowledgements
We thank Martin Wattenberg, Yonatan Belinkov, and Thomas Fel for feedback, and participants of the NEMI Workshop and the Mechanistic Interpretability Workshop at NeurIPS 2025 for helpful discussion. This work was supported by the Kempner Research Fellowship and the Schwartz Fellowship, with compute from the Kempner Institute cluster.