Motivation
Recurrent Network falls into the larger topic of sequence modelling.
Architecture
LSTM
The architecture of a LSTM module
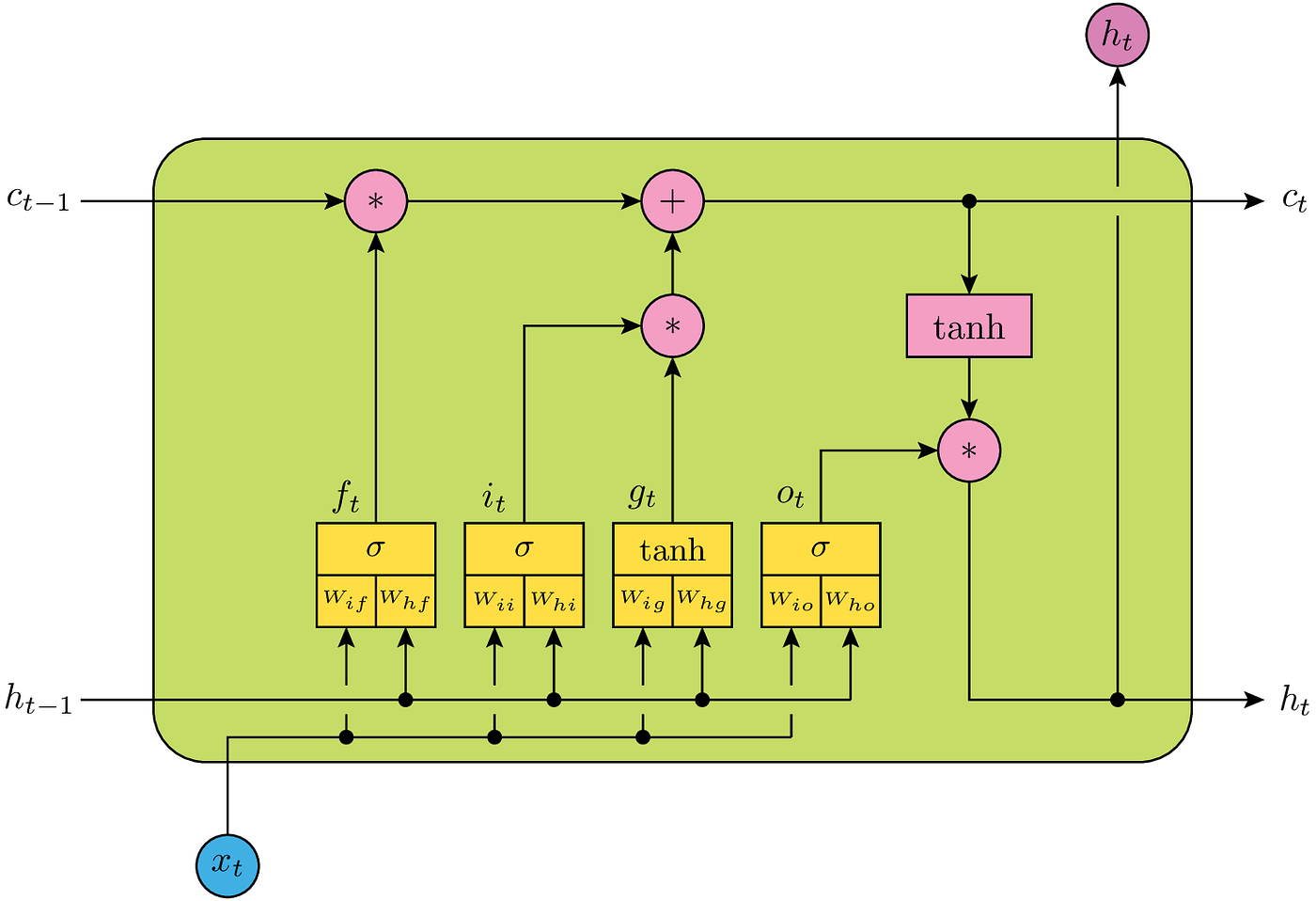
c_tis the cell memoryh_tis the hidden state
For each of the inner gate variables $f_t$, $i_t$, $g_t$, $o_t$ they are an non-linear function taking $h_{t-1}$ and $x_t$ as input and output the inner state at that moment.
GRU
Transformer
- Enhance parallelization
- Can learn to fetch data from different part of data
The key is the attention module, for each item in sequence (a representation vector) it propose a key, quest and value vector. Then use inner product of quest and key and soft-max normalization to form a attention matrix, then use this attention matrix to recombine the value vectors.
Training Practise
As recurrent network can be unrolled through time,
Some tricks for regularizing and optimizing LSTM based models introduced in Regularizing and Optimizing LSTM Language Models
Too many steps back in sequence is not easy to back prop, and it could induce gradient explosion or vanishing.