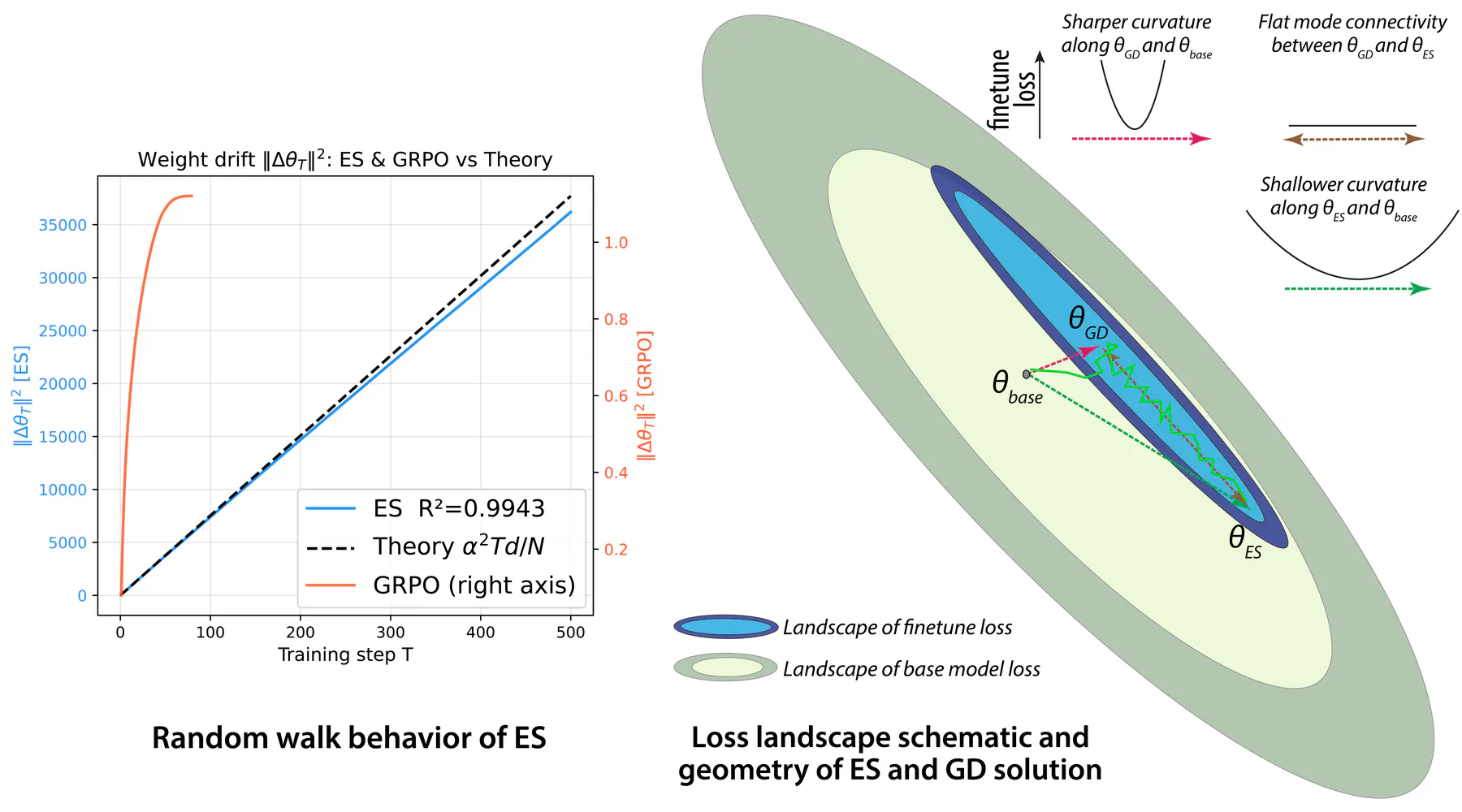
Matching Accuracy, Different Geometry: Evolution Strategies vs GRPO in LLM Post-trainingJan 1, 2026·William HoyBinxu Wang,Xu Pan· 0 min read PDFTypeJournal articlePublicationunder review at COLM 2026Last updated on Jan 1, 2026LLM Reinforcement Learning Science of AI Theory AuthorsBinxu WangResearch Fellow ← Differentiable Faithfulness Alignment for Cross-Model Circuit Transfer Jan 1, 2026Structure as an inductive bias for brain–model alignment Dec 4, 2025 →
 ,·
0 min read
,·
0 min read